Neste post, apresentaremos um tutorial de como reestruturar o formato do banco de dados no R. A linguagem R é uma ferramenta versátil para a manipulação de dados antes do ajuste dos modelos estatísticos propriamente ditos.
Para iniciar, vamos a uma descrição do problema. Existem dois formatos principais para estruturar seu banco de dados: o formato amplo (wide) e o formato longo (long). Nesse sentido, diferentes técnicas estatísticas pressupõem que o banco de dados está montado de maneiras distintas.
Primeiramente, explicaremos esses dois formatos de banco de dados, com exemplos. Em seguida, em duas seções independentes, explicaremos como reestruturar seu banco de dados no formato amplo para longo, e no formato longo para amplo. Essas seções são escritas de modo que você possa ler uma independentemente da outra. Finalmente, concluíremos o post com algumas sugestões de materiais sobre o R para você que tem interesse em psicometria e em análise quantitativa de dados.
O que são os formatos amplo e longo?
O que é banco de dados no formato amplo?
Antes de mais nada, vamos falar do formato amplo (wide). Com frequência, é nesse formato que tabulamos dados em softwares como Excel e SPSS. No formato amplo, cada linha representa um participante ou observação, e cada coluna representa uma variável distinta. Além disso, variáveis mensuradas múltiplas vezes são apresentadas em várias colunas, uma por mensuração.
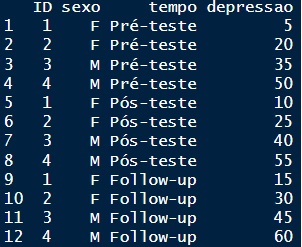
Por exemplo, a Figura 1 apresenta um banco de dados tabulados em formato amplo. Para fins didáticos, o banco de dados possui apenas quatro participantes. Na Figura 1, a coluna ID representa o código de identificação dos participantes e a coluna Sexo representa uma variável comum a todos os tempos do estudo. Por outro lado, escores de depressão foram mensurados em três ondas (pré-teste, pós-teste e follow-up), sendo, portanto, representados na tabela em colunas distintas.

O que é banco de dados no formato longo?
Em contrapartida, no formato longo, múltiplas linhas podem representar um mesmo participante. Em outras palavras, o número de vezes que cada participante se repete no banco de dados corresponde ao número de medidas repetidas existentes no estudo. No exemplo do estudo longitudinal que mencionamos anteriormente, três linhas distintas representam cada participante, uma para cada tempo de avaliação dos escores de depressão.
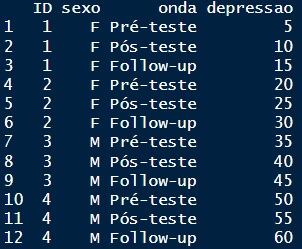
A Figura 2 apresenta um exemplo de banco de dados tabulados em formato longo, isto é, onde o número de linhas desse banco de dados é o produto do número de participantes pelo número de medidas repetidas (4 participantes × 3 medidas repetidas = 12 linhas). No banco de dados da Figura 2, portanto, uma única coluna aglutina as três medidas de depressão ao longo do tempo. Para sabermos a qual tempo cada linha se refere, uma nova coluna, denominada tempo, codifica as observações em pré-teste, pós-teste e follow-up.

Por que reestruturar banco de dados no R?
Em geral, testes t, correlações e regressões lineares e logísticas exigem que o banco de dados esteja no formato amplo, enquanto ANOVAs de medidas repetidas, modelos lineares mistos e equações de estimativas generalizadas exigem que o banco de dados esteja no formato longo.
Sendo assim, é importante que pesquisadores conheçam e saibam utilizar funções que transformem o banco de dados de um formato para o outro, conforme suas necessidades. Em seguida, mostraremos como podemos transformar o banco de dados de um formato para o outro usando a linguagem R.
Como reestruturar banco de dados de amplo para longo no R?
Como preparar o material
Neste tutorial, assumiremos que o banco de dados está armazenado como um objeto do tipo data.frame, no R. Esse tipo de estrutura é similar às planilhas do Excel com as quais você já pode ter alguma familiaridade. Na sequência do post, os termos banco de dados e data.frame serão usados de maneira intercambiável.
Antes de mais nada, instalaremos e carregaremos o pacote que utilizaremos no tutorial.
# instalando e carregando o stats
install.packages("stats")
library(stats)
Em seguida, criaremos um banco de dados similar à representação da Figura 1. O código a seguir atinge esse objetivo.
# dados em formato amplo (similar à Figura 1)
dados_amplo <- data.frame(ID = rep(1:4),
sexo = c("F", "F", "M", "M"),
depressao_pre = c(5, 20, 35, 50),
depressao_pos = c(10, 25, 40, 55),
depressao_follow = c(15, 30, 45, 60)
)
head(dados_amplo)

Note que o data.frame acima possui quatro linhas, cada uma delas representando um participante, similar à representação de banco de dados em formato amplo da Figura 1.
Como reestruturar o banco de dados no R
A seguir, nossa tarefa será reestruturar o banco de dados com o R, no caminho amplo para longo (wide to long). Para isso, usaremos a função reshape, do pacote stats, conforme indicado no código a seguir.
# reestruturando dados no caminho amplo para longo
dados_amplo_para_longo <- stats::reshape(data = dados_amplo,
idvar = c("ID", "sexo"),
varying = list(c("depressao_pre",
"depressao_pos",
"depressao_follow")),
v.names = "depressao",
timevar = "tempo",
times = c("Pré-teste",
"Pós-teste",
"Follow-up"),
direction = "long")
No código anterior, invocamos a função reshape e atribuímos seu valor de retorno ao objeto dados_amplo_para_longo. A função reshape recebe os seguintes argumentos:
data: o dataframe que queremos reestruturar;idvar: especifica quais variáveis serão mantidas como identificadores no formato longo (i.e., as variáveis que não mudarão ao longo do tempo);varying: indica as colunas do banco de dados original que deverão ser transformadas em uma única coluna;v.names: define o nome da nova coluna que aglutinará os valores passados como argumentos paravarying;timevar: define o nome da coluna que indicará o tempo da mensuração em cada linha;times: define os valores que a colunatempodevem assumir;direction: indica para qual direção estamos reestruturando nossos dados.
Em nosso exemplo, atribuímos o resultado da operação a dados_amplo_para_longo. Por fim, executamos o código a seguir, que remove os nomes das linhas.
# limpa nomes das linhas do novo banco de dados
row.names(dados_amplo_para_longo) <- NULL
# e mostra as 12 linhas do novo banco de dados
head(dados_amplo_para_longo, 12)
Em síntese, obtemos o banco de dados em formato longo, similar àquele apresentado na Figura 2. Além disso, nós também poderíamos alterar a ordem de apresentação das linhas da representação acima, de modo que ela fique idêntica à Figura 2. Contudo, essa manipulação vai além do escopo desse tutorial.
Como reestruturar banco de dados de longo para amplo no R?
Como preparar o ambiente
Neste tutorial, assumiremos que o banco de dados está armazenado como um objeto do tipo data.frame, no R. Esse tipo de estrutura é similar às planilhas do Excel com as quais você já pode ter alguma familiaridade. Daqui em diante, os termos banco de dados e data.frame serão usados de maneira intercambiável.
Antes de mais nada, instalaremos e carregaremos o pacote que utilizaremos no tutorial.
# instalando e carregando o stats
install.packages("stats")
library(stats)
Em seguida, criaremos um banco de dados similar à representação da Figura 2. O código a seguir atinge esse objetivo.
# dados em formato longo (similar à Figura 2)
dados_longo <- data.frame(ID = rep(1:4, each = 3),
sexo = rep(c("F", "M"), each = 6),
onda = rep(c("Pré-teste",
"Pós-teste",
"Follow-up"), by = 4),
depressao = seq(from = 5, to = 60, by = 5))
head(dados_longo, 12)
Como reestruturar o banco de dados no R
A seguir, nossa tarefa será reestruturar o banco de dados com o R, no caminho longo para amplo (long to wide). Para isso, usaremos a função reshape, do pacote stats, conforme indicado no código a seguir.
# reestruturando dados no caminho longo para amplo
dados_longo_para_amplo <- stats::reshape(data = dados_longo,
idvar = c("ID", "sexo"),
timevar = "onda",
direction = "wide")
No código anterior, invocamos a função reshape e atribuímos seu valor de retorno ao objeto dados_longo_para_amplo. A função reshape recebe os seguintes argumentos:
data: o dataframe que queremos reestruturar;idvar: especifica quais variáveis serão mantidas como identificadores no formato longo (i.e., as variáveis que definirão o número de linhas no novo banco de dados);timevar: variável que diferencia os registros de um mesmo caso;direction: indica para qual direção estamos reestruturando nossos dados.
Em nosso exemplo, atribuímos o resultado da operação a dados_longo_para_amplo. Por fim, executamos o código a seguir, que remove os nomes das linhas.
# renomeia nomes das colunas
colnames(dados_longo_para_amplo) <- c("ID", "sexo", unique(dados_longo$onda))
# e mostra as 4 linhas do novo banco de dados
head(dados_longo_para_amplo, 4)

Em síntese, obtemos o banco de dados em formato amplo, similar àquele apresentado na Figura 1.
Conclusão
Neste tutorial, você aprendeu o que são bancos de dados nos formatos amplo (wide) e longo (long). Além disso, em dois tutoriais simples, você aprendeu como reestruturar o banco de dados no R, indo de um formato para o outro. Para atingir esses objetivos, utilizamos a linguagem R, uma ferramenta poderosa para pesquisadores em análise quantitativa de dados.
Quer aprender mais sobre R? Então veja a novidade que preparamos a seguir!
É com grande satisfação que a Psicometria Online anuncia o curso R para Iniciantes. O curso tem como objetivo abordar todos os tópicos essenciais do R, permitindo que você explore assuntos específicos sem ser prejudicado por dúvidas básicas. Se você trabalha com pesquisa científica e deseja aprender a utilizar o R, então o curso R para Iniciantes é para você.

Além disso, se você quer saber mais sobre a Psicometria Online Academy, acesse nosso site. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).
Referência
Field, A., Miles, J., & Field, Z. (2012). Discovering statistics using R. Sage.
Como citar este post
Lima, M. (2024, 8 de julho). Como reestruturar o formato do banco de dados no R? Blog Psicometria Online. https://www.blog.psicometriaonline.com.br/como-reestruturar-banco-de-dados-no-r/