No teste de significância da hipótese nula, tomamos decisões sobre rejeitar ou não uma dada hipótese. No entanto, esse processo é suscetível a erros. Neste post, explicaremos um desses erros na inferência frequentista: o erro Tipo I.
O que são hipóteses alternativa e nula?
Em estatística frequentista, a hipótese nula (H0) é aquela que buscamos nulificar, isto é, refutar. Tradicionalmente, essa hipótese afirma que não existe efeito ou relação entre variáveis. Já a hipótese alternativa (H1) afirma o contrário, ou seja, que existe um efeito ou relação entre variáveis.
Por exemplo, suponha que investigamos o efeito do consumo de café sobre a produtividade acadêmica, definida operacionalmente como o número de páginas redigidas em um dia. Nesse exemplo, podemos formular as seguintes hipóteses:
- Hipótese nula (H0): não existem diferenças no número de páginas redigidas entre aqueles que consomem e aqueles que não consomem café;
- Hipótese alternativa (H1): existem diferenças no número de páginas redigidas entre aqueles que consomem e aqueles que não consomem café.

Qual é a diferença entre nível de significância e valor de p?
Ao realizar um teste de significância da hipótese nula, definimos o nível de significância (α, letra grega alfa), que representa a probabilidade de rejeitar a hipótese nula, se ela for verdadeira. Esse valor reflete o quão improvável os dados precisam ser, assumindo que a hipótese nula é verdadeira, para decidirmos rejeitar essa hipótese.
Depois de coletar os dados, obtemos um valor de p, que indica a probabilidade de observarmos uma estatística tão extrema (ou mais) quanto a encontrada, caso a hipótese nula seja verdadeira.
Embora semelhantes, esses conceitos não são sinônimos. O nível de significância é definido antes das análises, enquanto o valor de p é calculado na própria análise de dados.
O salto em altura é um esporte que fornece uma metáfora útil para distinguirmos esses dois conceitos: o alfa representa a altura da barra (critério de sucesso), enquanto o valor de p reflete o salto em si (resultado real). Se o salto (valor de p) superar ou for igual à altura da barra (nível alfa), então rejeitamos a hipótese nula (Figura 1).

O que é erro Tipo I?
Mesmo quando rejeitamos a hipótese nula com base no valor de p, existe a chance dessa hipótese ser verdadeira. Se isso ocorrer, cometemos o erro Tipo I. Em outras palavras, o erro Tipo I consiste em rejeitar a hipótese nula, quando ela é verdadeira.
Na realidade, quando definimos o nível alfa, significa que estamos dispostos a tomar a decisão incorreta de rejeitar a hipótese nula, quando ela for verdadeira, em até 5% das vezes que realizarmos um teste de hipótese.
Ao definir α = 0,05, estamos aceitando uma margem de erro em que rejeitaremos a hipótese nula verdadeira em até 5% dos casos. No entanto, se quisermos adotar um critério mais conservador, podemos usar α = 0,01, reduzindo esse erro para 1%, o que exige dados mais surpreendentes para rejeitar a hipótese nula.
Contudo, ao reduzir o erro Tipo I, aumentamos a probabilidade de cometer o erro Tipo II, que ocorre quando não rejeitamos uma hipótese nula falsa. O desafio, portanto, está em equilibrar esses dois tipos de erro.
Por fim, vale observar que, em algumas situações de pesquisa, o erro Tipo I pode estar sendo inflado sistematicamente, por conta do número de testes estatísticos realizados. Quando queremos realizar múltiplos testes, mantendo a taxa nominal de erro Tipo I em 5% (ou em outro valor especificado), precisamos realizar algum tipo de correção para comparações múltiplas, como a correção de Bonferroni.
Como me lembrar do que é erro Tipo I e erro Tipo II?
Diferenciar os erros dos Tipos I e II pode ser inicialmente difícil. Desse modo, visando facilitar essa diferenciação, apresentamos um exemplo: considere a hipótese nula “uma pessoa não está grávida”. A Figura 2 ilustra os dois tipos de erros, a depender da veracidade ou falsidade dessa hipótese nula e da decisão tomada sobre rejeitá-la ou não.
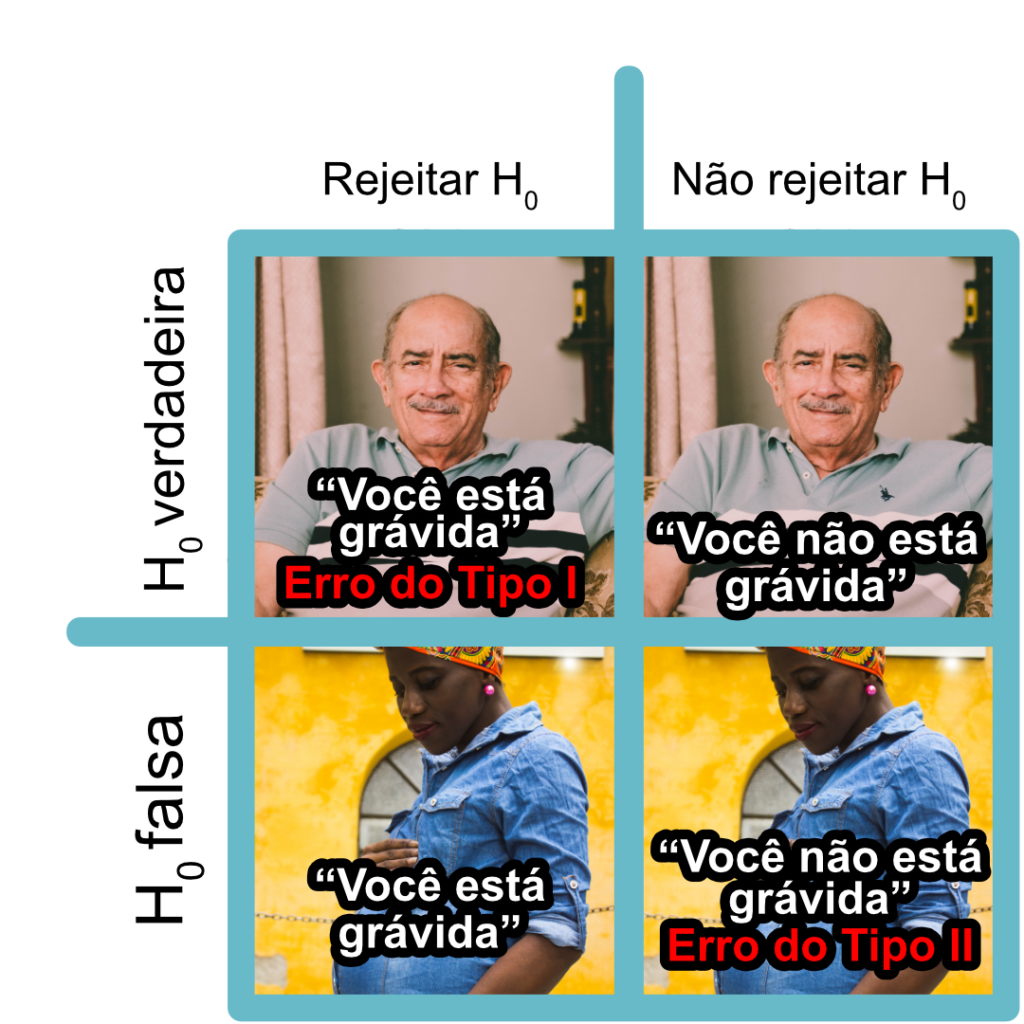
O erro Tipo I ocorre quando afirmamos que a pessoa está grávida (rejeitamos a hipótese nula), mas ela não está, isto é, cometemos um falso positivo (Figura 2, célula no canto superior esquerdo).
Por outro lado, o erro Tipo II acontece quando não afirmamos que a pessoa está grávida (não rejeitamos a hipótese nula), mas ela de fato está grávida, isto é, cometemos um falso negativo (Figura 2, célula no canto inferior direito).
Veja também: O que é erro Tipo II?
Conclusão
Neste post, explicamos o conceito de erro Tipo I. Além disso, relacionamos esse erro ao erro Tipo II, que também deve ser considerado quando conduzimos testes de significância da hipótese nula.
Gostou desse conteúdo? Para seguir acompanhando nossas novidades, inscreva-se em nosso canal do YouTube.
Se você precisa aprender análise de dados, então faça parte da Psicometria Online Academy, a maior formação de pesquisadores quantitativos da América Latina. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).
Referência
Field, A. (2017). Discovering statistics using IBM SPSS Statistics (5th ed.). Sage.
Como citar este post
Lima, M. (2021, 21 de maio). O que é erro Tipo I? Blog Psicometria Online. https://www.blog.psicometriaonline.com.br/o-que-e-erro-do-tipo-i/