

Centralizar os dados é uma técnica estatística amplamente utilizada em pesquisas quantitativas, pois ela traz algumas vantagens para pesquisadores.
Neste post, explicaremos o que é centralizar os dados, quais são seus benefícios e como realizar essa técnica no SPSS. Por fim, descreveremos como a interpretação do intercepto em um modelo de regressão é modificada após o procedimento de centralização.

O que é centralizar os dados?
Centralizar os dados consiste em subtrair algum valor constante (em geral, a média de uma variável) de cada valor individual dessa variável. Por exemplo, na centralização pela média, temos:
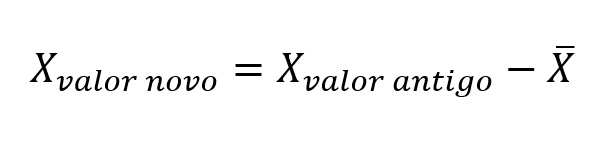
onde X-barra representa a média amostral.
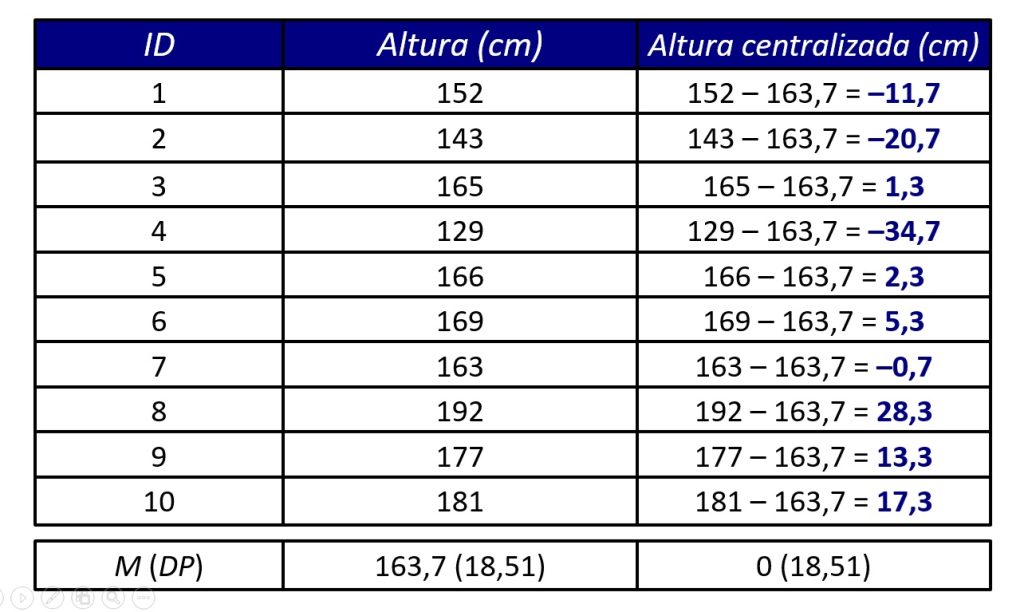
Por exemplo, a Figura 1 apresenta a altura de 10 pessoas. A coluna Altura centralizada (cm) calcula o desvio da altura de cada altura em relação à média de alturas. Nessa nova medida, valores negativos representam alturas abaixo da média original, enquanto valores positivos representam alturas acima da média original; um valor nulo, inexistente na Figura 1, representaria uma altura idêntica à média de alturas da amostra.
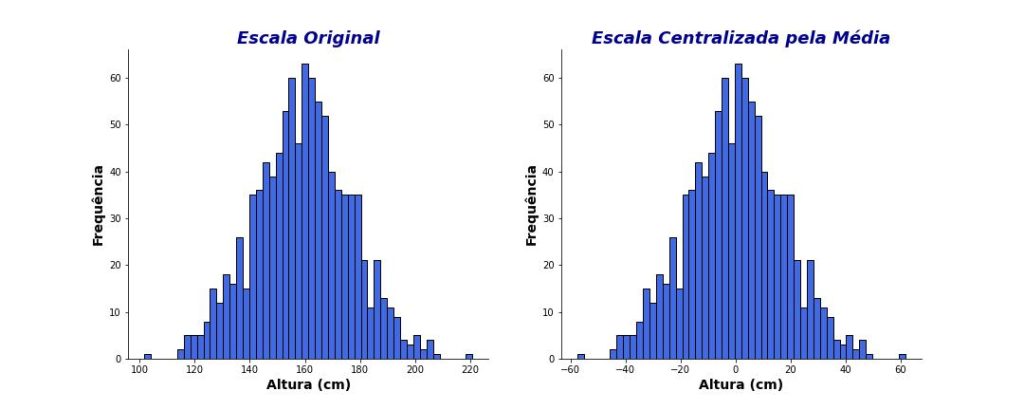
Como podemos ver na parte inferior da Figura 1, centralizar pela média impacta a média da variável transformada, mas não sua variabilidade (i.e., desvio-padrão). A Figura 2 ilustra essa ideia com uma amostra de mil casos. Embora as distribuições de alturas nas duas escalas sejam idênticas, a distribuição de alturas na escala centralizada pela média gira ao redor de zero, isto é, o valor da nova média amostral.
Em seguida, veremos que essa característica da centralização pode ser útil para a interpretação de modelos estatísticos.
Quais são os benefícios de centralizar os dados?
Primeiramente, centralizar os dados dá sentido aos escores individuais. Em outras palavras, saber que um escore centralizado pela média é menor, igual ou maior que zero traz informações sobre seu valor em relação à média amostral. Por exemplo, o ID = 1 da Figura 1 tem um escore de –11,7, isto é, 11,7 pontos abaixo da média amostral.
Além disso, considere que queremos predizer o desempenho dos participantes em uma tarefa psicomotora usando a altura dos participantes como variável preditora. Nesse caso, temos o seguinte modelo de regressão:
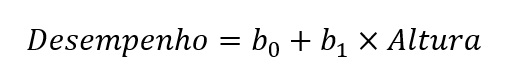
onde o valor do intercepto, b0, indica o desempenho previsto pelo modelo de regressão quando a altura de um participante é zero. No entanto, sempre que a variável preditora não tiver um zero com significado interpretável (i.e., você conhece alguém com altura igual a zero?), o intercepto também não será interpretável.
Agora, considere o modelo de regressão alternativo:
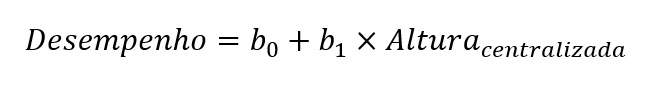
onde a variável Alturacentralizada = Altura – (Média da altura), tal como calculado na Figura 1. No novo modelo, o coeficiente b0 estima o desempenho quando a altura de um participante é zero, isto é, igual à média amostral na variável Alturacentralizada.
Desse modo, um segundo benefício de centralizar uma variável pela média é que isso fornece uma interpretação ao intercepto.
Por fim, considere o seguinte modelo de moderação:
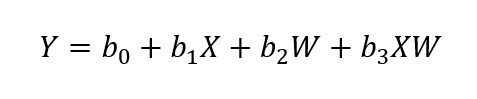
Nesse modelo, os efeitos de X sobre Y (b1) são contingentes aos níveis da variável moderadora W. Aqui, centralizar as variáveis preditoras pelas médias tornam seus efeitos interpretáveis, sem que isso afete o efeito de interação. Por exemplo, se X e W forem centralizadas antes da análise, o coeficiente b1 estimará a diferença em Y entre dois casos que diferem em uma unidade em X para os casos com o valor médio em W.
Como centralizar os dados no SPSS?
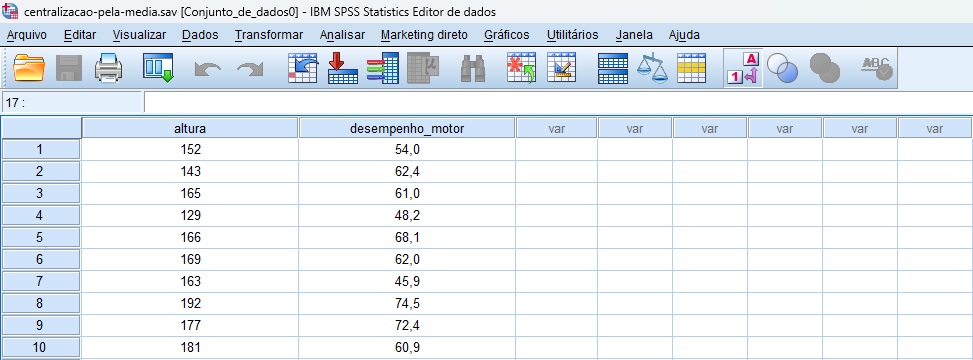
A Figura 3 apresenta um banco de dados no SPSS, similar aos dados descritos na Figura 1.
Calculando a média amostral
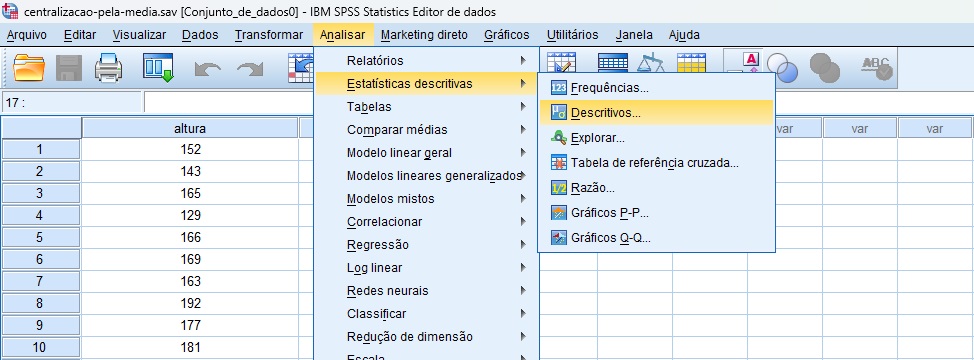
Primeiramente, precisamos identificar a média amostral que será usada no procedimento de centralização. Para esse fim, siga o caminho Analisar > Estatísticas descritivas > Descritivos (Figura 4).
Em seguida, transfira para a caixa Variável(is) a variável (ou as variáveis) que você deseja obter a média (em nosso caso, altura) e clique em OK (Figura 5).

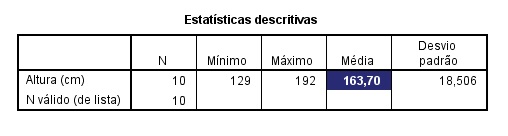
A Figura 6 ilustra a saída gerada pelo SPSS, com destaque para o valor da média de altura, de 163,70.
Criando a variável centralizada
Para criarmos a nova variável centralizada, seguiremos o caminho Transformar > Calcular variável (Figura 7).
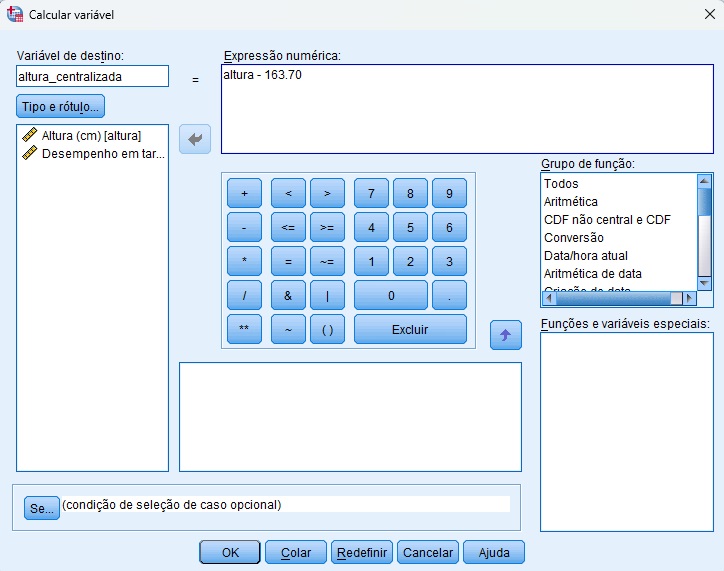
Em seguida, daremos o nome altura_centralizada para a nova variável que criaremos em nosso banco de dados (Figura 8). Além disso, informaremos ao SPSS qual expressão numérica será usada para criar a nova variável no banco de dados.
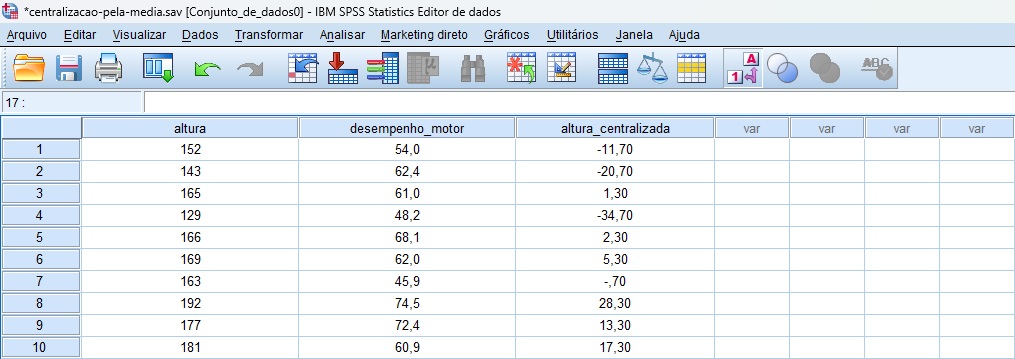
Após clicar em OK, o SPSS criará uma nova coluna no banco de dados, conforme indicado na Figura 9. Como você pode ver, cada entrada nessa coluna representa o valor da altura original menos a média amostral (compare as Figuras 1 e 9 deste tutorial).
Comparando interceptos de modelos de regressão
Anteriormente, afirmamos que a centralização pela média dá uma interpretação significativa (no sentido não estatístico) do intercepto em modelos de regressão. Os resultados de dois modelos de regressão linear simples apoiam essa afirmativa (Figura 10).
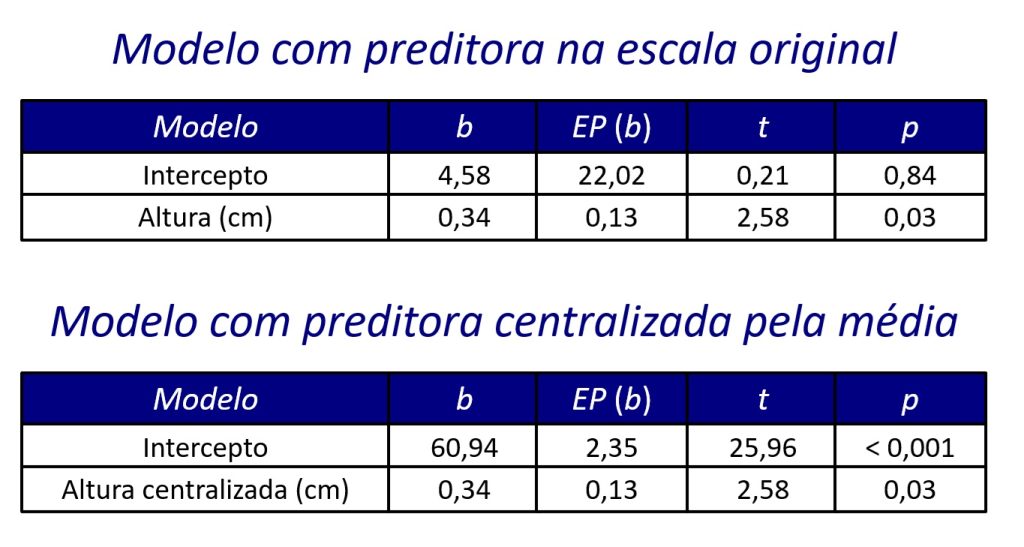
Primeiramente, o coeficiente b1 é idêntico nos dois modelos, o que indica que a centralização não altera a interpretação do coeficiente associado à variável preditora.
Em segundo lugar, o valor do intercepto é modificado pela centralização. No painel superior, b0 = 4,58 indica o desempenho previsto na tarefa psicomotora para alguém com altura = 0. No entanto, isso não faz sentido, pois é impossível ter uma altura igual a zero.
Em contrapartida, no painel inferior, b0 = 60,94 indica o desempenho previsto na tarefa psicomotora para alguém com altura igual à média amostral. Em outras palavras, na ausência de preditores no modelo de regressão, o melhor palpite que temos do desempenho de um participante é a própria média de desempenhos nessa tarefa psicomotora. Contudo, essa interpretação é possível apenas após a centralização da variável altura.
Conclusão
Neste post, você aprendeu o que é centralizar uma variável e quais são os principais benefícios dessa técnica. Além disso, você aprendeu a centralizar uma variável no SPSS. Por fim, ensinamos como a interpretação do intercepto de um modelo de regressão muda após o procedimento de centralização.
Gostou desse conteúdo? Se você precisa aprender análise de dados, então faça parte da Psicometria Online Academy, a maior formação de pesquisadores quantitativos da América Latina. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).
Referências
Field, A. (2017). Discovering statistics using IBM SPSS Statistics (5th ed.). Sage.
Hayes, A. F. (2022). Introduction to mediation, moderation, and conditional process analysis: A regression-based approach (3rd ed.). The Guilford Press.
Como citar este post
Lima, M. (2024, 2 de outubro). Como centralizar os dados no SPSS? Blog Psicometria Online. https://www.blog.psicometriaonline.com.br/como-centralizar-os-dados-no-spss













