

Neste post, apresentaremos um tutorial de como juntar bancos de dados no R usando o pacote dplyr.
Nós aqui usamos o termo bancos de dados como sinônimo de data.frame. Em outras palavras, um data.frame é uma estrutura de dados bidimensional, onde cada coluna representa uma variável, e cada linha representa um participante ou observação. Esse tipo de estrutura é similar às planilhas do Excel com as quais você já pode ter alguma familiaridade. Ao longo do tutorial, os termos banco de dados e data.frame serão usados de maneira intercambiável.
Descrição do problema
A princípio, assuma que você coletou dados de uma amostra em duas sessões distintas. Portanto, você possui dois bancos de dados, um para cada tempo de sua coleta de dados.
Juntar bancos de dados é relativamente simples em softwares como o Excel, pois você precisa apenas ter uma chave de identificação (como nome ou número de matrícula dos participantes) presente nos bancos de dados que deseja unir. Em seguida, ordene os bancos de dados com base na coluna contendo a chave de identificação dos participantes e copie e cole as informações do primeiro banco de dados lado a lado com o fim das colunas do segundo banco de dados.
No entanto, podem surgir dificuldades. Por exemplo, alguns participantes podem ter dados ausentes na primeira ou na segunda sessão, o que pode resultar em bancos de dados com chaves de identificação diferentes. Assim, mesmo após ordenarmos os bancos de dados com base na coluna contendo a chave de identificação, as linhas podem não estar totalmente alinhadas nos dois bancos.
Portanto, na pesquisa científica que envolve múltiplos bancos de dados, o desafio é como unir esses bancos de dados da maneira mais rápida e eficiente possível. Em seguida, demonstraremos como juntar bancos de dados no R.
O pacote dplyr
A solução que apresentaremos usará o pacote dplyr. O dplyr é um pacote da linguagem R usado para manipulação de dados, isto é, em tarefas de organização de bancos de dados que antecedem as análises estatísticas propriamente ditas.
No R, o dplyr pode ser instalado e carregado por meio do código a seguir.
# instalanco e carregando o dplyr
install.packages("dplyr")
library(dplyr)
Você deve executar o código da linha 2 uma única vez. Por outro lado, você deve executar o código da linha 3 sempre que iniciar uma nova sessão no R. Além disso, R ou RStudio ignora as linhas iniciadas com #, tratando-as como comentários durante a execução do código.
O pacote possui quatro funções principais para juntar bancos de dados no R. Ademais, cada uma delas é indicada para um tipo distinto de junção entre bancos de dados. Portanto, é importante que você saiba exatamente como cada uma delas funciona, para que escolha a ferramenta mais adequada ao seu problema.
Para entendermos o comportamento de cada uma das funções join do dplyr, criaremos dois bancos de dados simplificados.
# dados da sessão 1
sessao1 <- data.frame(ID = c("A", "B", "C", "D"),
X = 1:4,
Y = 5:8)
# dados da sessão 2
sessao2 <- data.frame(ID = c("C", "D", "E", "F"),
W = 9:12,
Z = 13:16)
O código anterior cria dois bancos de dados, em formato data.frame, conforme representados na Figura 1.
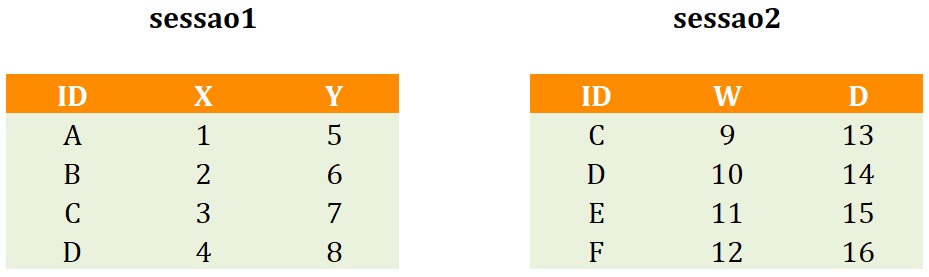
Primeiramente, cada um dos bancos de dados do tutorial tem apenas 4 casos. As colunas de identificação dos bancos de dados (ID) dos data.frames sugerem que apenas dois participantes ( identificados nas colunas ID como C e D) contribuíram com dados nas duas sessões. A sessão 1 contém as medidas X e Y, e a sessão 2, as medidas W e Z. Esses dados poderiam representar um delineamento que inicialmente coletou duas variáveis preditoras e, posteriormente, duas variáveis de resultado.
Como juntar bancos de dados no R com a função inner_join()?
Começaremos nosso tutorial pela função inner_join(). Em síntese, o inner_join():
- Recebe dois
data.frames, o primeiro sendo considerado odata.frameà esquerda, e o segundo sendo considerado odata.frameà direita; - Por meio do argumento
by, recebe o nome de uma coluna que representa a chave de identificação que unirá os dois bancos de dados; - Inclui as linhas que estão contidas em ambos os
data.framesao mesmo tempo; - Inclui as variáveis contidas em pelo menos um dos
data.frames.
Nesse sentido, concluímos que a função se assemelha à operação matemática de intersecção entre conjuntos. O código a seguir implementa o inner_join(). A Figura 2 apresenta o banco de dados resultante da aplicação da função.
# inner_join()
dados_inner <- dplyr::inner_join(sessao1,
sessao2,
by = "ID")
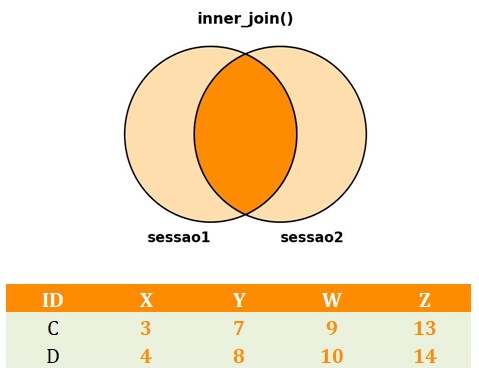
Inner_join().Como juntar bancos de dados no R com a função left_join()?
A função left_join():
- Recebe dois
data.frames, o primeiro sendo considerado odata.frameà esquerda, e o segundo sendo considerado odata.frameà direita; - Por meio do argumento
by, recebe o nome de uma coluna que representa a chave de identificação que unirá os dois bancos de dados; - Inclui todas as linhas que estão contidas no
data.frameà esquerda; - Inclui as variáveis contidas em pelo menos um dos
data.frames; - Atribui valores
NAàs células em que não contêm observação em uma dada variável para um dado participante. No R,NAquer dizer not available, representando dados ausentes.
O código a seguir implementa o left_join(). A Figura 3 apresenta o banco de dados resultante da aplicação da função.
# left_join()
dados_left <- dplyr::left_join(sessao1,
sessao2,
by = "ID")
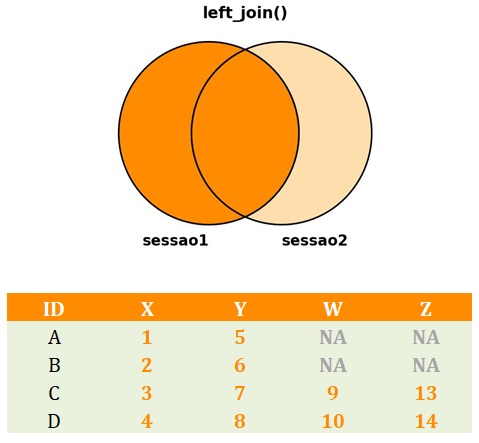
Left_join().Como juntar bancos de dados no R com a função right_join()?
O right_join() tem um comportamento parecido com o do left_join(). O right_join():
- Recebe dois
data.frames, o primeiro sendo considerado odata.frameà esquerda, e o segundo sendo considerado odata.frameà direita; - Por meio do argumento
by, recebe o nome de uma coluna que representa a chave de identificação que unirá os dois bancos de dados; - Inclui todas as linhas que estão contidas no dataframe à direita;
- Inclui as variáveis contidas em pelo menos um dos
data.frames; - Atribui
NAàs células em que não contêm observação em uma dada variável para um dado participante.
O código a seguir implementa o right_join(). A Figura 4 apresenta o banco de dados resultante da aplicação da função.
# right_join()
dados_right <- dplyr::right_join(sessao1,
sessao2,
by = "ID")
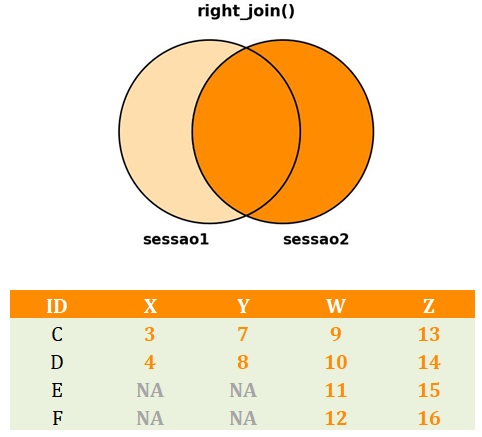
Right_join(). Como juntar bancos de dados no R com a função full_join()?
Por fim, o full_join():
- Recebe dois
data.frames, o primeiro sendo considerado odata.frameà esquerda, e o segundo sendo considerado odata.frameà direita; - Por meio do argumento
by, recebe o nome de uma coluna que representa a chave de identificação que unirá os dois bancos de dados; - Inclui as linhas contidas em pelo menos um dos
data.frames; - Inclui as variáveis contidas em pelo menos um dos
data.frames; - Atribui
NAàs células em que não contêm observação em uma dada variável para um dado participante.
Neste último caso, o banco de dados resultante irá conter todos os participantes da pesquisa, independentemente de terem contribuído ou não em todas as sessões com dados. O código a seguir implementa o full_join(). A Figura 5 apresenta o banco de dados resultante da aplicação da função.
# full_join()
dados_full <- dplyr::full_join(sessao1,
sessao2,
by = "ID")
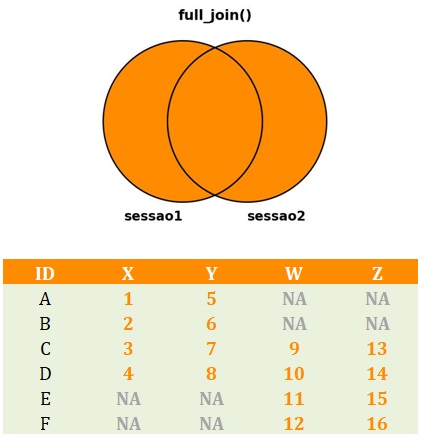
Full_join(). Como usar o join com bancos de dados contendo variáveis com nomes iguais?
No cenário hipotético deste tutorial, coletamos as variáveis X e Y na sessão 1, enquanto as variáveis W e Z foram coletadas na sessão 2. No entanto, suponha que a pesquisa coletou apenas as variáveis X e Y nas duas sessões. Tal situação acontece em delineamentos de medidas repetidas.
No novo cenário, portanto, teríamos conflito de variáveis. Desse modo, as funções join do pacote dplyr resolveriam a ambiguidade nos nomes das colunas acrescentando um .x no final dos nomes das variáveis do data.frame à esquerda, e um .y nos nomes das variáveis do data.frame à direita. Veja o que aconteceria, por exemplo, se usássemos o inner_join(), conforme ilustrado no banco de dados da Figura 6.
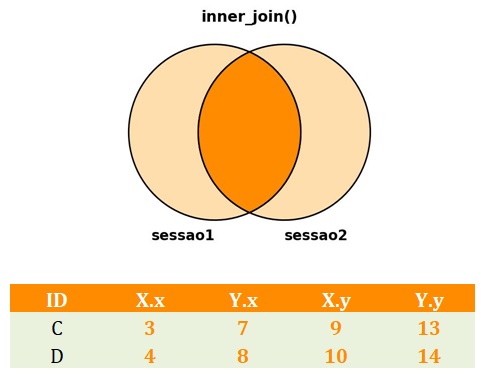
inner_join() ao ser aplicado em data.frames com colunas com nomes iguais.No entanto, vale notar que todas as funções join têm um argumento opcional suffix que, por padrão, recebe uma lista com os valores .x e .y. Podemos mudar esse comportamento para termos nomes mais informativos.
# renomeando colunas de sessao2
# agora nomes das colunas coincidirão nos dois data.frames
colnames(sessao2) <- c("ID", "X", "Y")
teste <- dplyr::inner_join(sessao1,
sessao2,
by = "ID",
suffix = c("_sessao1",
"_sessao2"))
E eis o novo resultado na Figura 7.
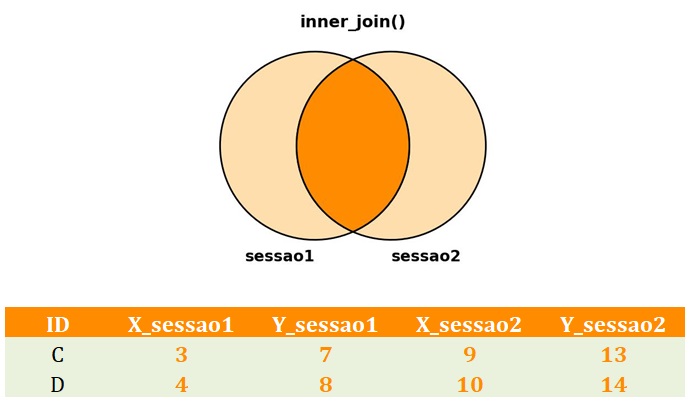
Inner_join() usando o parâmetro opcional suffix. Em síntese, um vetor é passado como parâmetro para suffix. Sempre que a função join encontrar colunas com conflito de nomes nos dois data.frames, ela acrescentará ao final do nome original o sufixo sessao1 às colunas do data.frame à esquerda, e o sufixo _sessao2 às scolunas do data.frame à direita. Por outro lado, as colunas sem conflitos de nomes nos dois bancos de dados não receberão os sufixos.
Conclusão
Neste post, você aprendeu como juntar bancos de dados com o R usando o pacote dplyr.
É com grande satisfação que a Psicometria Online anuncia o curso R para Iniciantes. O curso tem como objetivo abordar todos os tópicos essenciais do R, permitindo que você explore assuntos específicos sem ser prejudicado por dúvidas básicas. Se você trabalha com pesquisa científica e deseja aprender a utilizar o R, então o curso R para Iniciantes é para você.

Além disso, se você quer saber mais sobre a Psicometria Online Academy, acesse nosso site. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).
Referência
Wickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd ed.). O’Reilly.
Como citar este post
Lima, M. (2024, 8 de julho). Como juntar bancos de dados no R com o dplyr? Blog Psicometria Online. https://www.blog.psicometriaonline.com.br/como-juntar-bancos-de-dados-no-r/













