
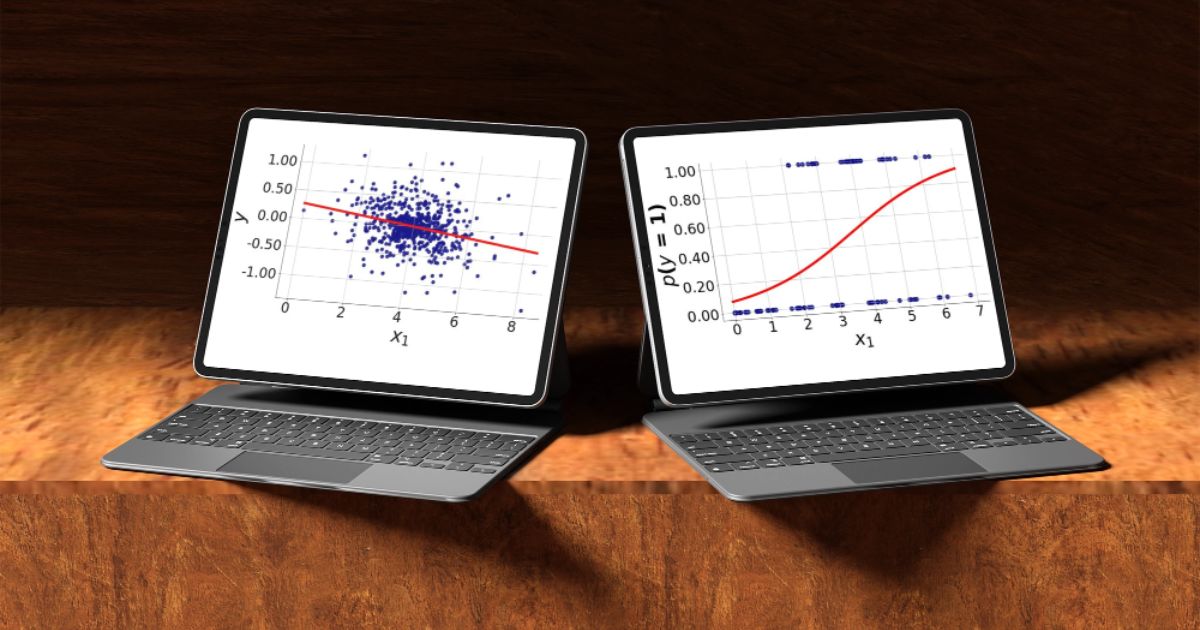
Na análise quantitativa de dados, a regressão é uma técnica fundamental para investigarmos relações preditivas entre variáveis. Existem diferentes tipos de técnicas de regressão, mas, neste post, abordaremos duas delas, a saber, regressão linear e regressão logística.
Sendo assim, o objetivo do post é apresentar brevemente cada um desses tipos de regressão para, em seguida, explicitarmos suas três principais diferenças.
Terminologia inicial
A fim de estabelecermos um vocabulário comum, introduziremos uma série de termos que serão usados a seguir.
Variável critério é aquela que queremos explicar ou predizer em nossos modelos estatísticos. Ela também é conhecida como variável dependente ou variável de resultado, em certos contextos.
Em contrapartida, a variável preditora é aquela que usamos para predizer os valores da variável critério. Ela também é conhecida como variável independente ou variável antecedente.
Nossos modelos de regressão podem ser simples ou múltiplos. Chamamos uma regressão de simples quando ela possui apenas uma variável preditora, enquanto uma regressão é chamada de múltipla quando possui duas ou mais variáveis preditoras. Contudo, ambas as regressões simples e múltipla possuem uma única variável critério.

O que é regressão linear?
A regressão linear é uma técnica em que a variável critério é contínua ou aproximadamente contínua. Seu objetivo é estimar os parâmetros de uma equação que melhor explica a relação linear entre uma variável critério e uma ou mais variáveis preditoras. Podemos representar a equação básica da regressão linear múltipla da seguinte forma:
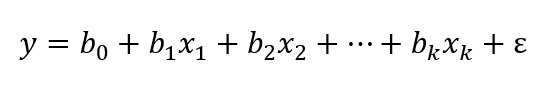
Onde y representa a variável critério do modelo, x1, x2, …, xk são as variáveis preditoras, b₀, b₁, b₂, …, bk são os coeficientes de regressão não padronizados e ε é o termo de erro. Em alguns casos, apresenta-se a fórmula substituindo os bs por βs (letra grega beta), para indicar que os coeficientes de regressão foram padronizados.
A regressão linear é amplamente utilizada para prever ou estimar valores numéricos contínuos com base em uma ou mais variáveis explicativas.
Por exemplo, podemos querer investigar se a qualidade de parentagem dos cuidadores prediz o nível de agressividade dos filhos. Em nosso exemplo, a qualidade de parentagem é a variável preditora, e o nível de agressividade, a variável critério. Apresentamos dados hipotéticos desse exemplo na Figura 1.
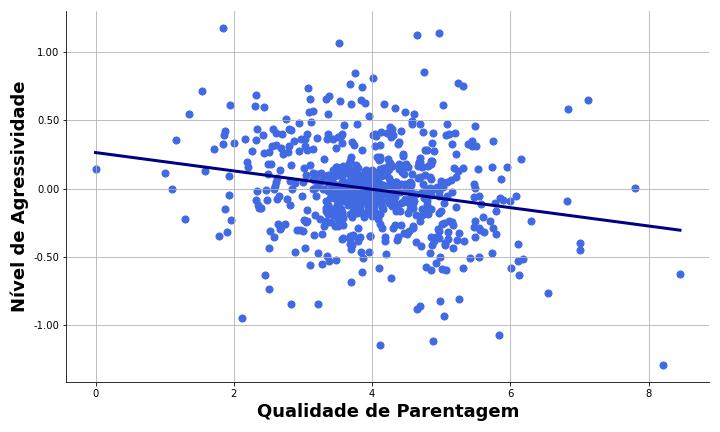
A Figura 1 sugere que quanto menor a qualidade de parentagem, maiores os níveis de agressividade das crianças. De fato, por meio da regressão linear, é possível propor um modelo que estime a reta de melhor ajuste que descreve a relação entre variáveis.
Para fins didáticos, restringimo-nos ao caso da regressão linear simples, com apenas uma variável preditora. Contudo, poderíamos inserir outras preditoras em nosso modelo, tais como tempo assistindo televisão, tempo de jogos de videogame e nível socioeconômico da família, para citar algumas possibilidades.
O que é regressão logística?
A regressão logística é uma técnica em que a variável critério é categórica. Ela estima a probabilidade de pertencimento a diferentes categorias (e.g., usar preservativos vs. não usar preservativos; adoecer vs. não adoecer; ser solteiro vs. casado vs. viúvo).
Podemos representar a regressão logística binária da seguinte maneira:
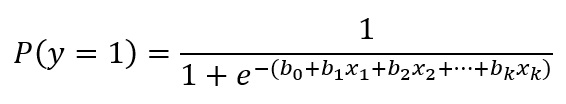
Onde p(y = 1) representa a probabilidade de um caso fazer parte da categoria = 1 da variável critério. Os demais valores são similares à equação anterior. Já a presente equação restringe os valores de saída entre 0 e 1, como deve ocorrer com probabilidades.
Por exemplo, podemos testar se o risco percebido de relação sexual desprotegida aumenta a probabilidade de usar preservativo. O risco percebido de relação sexual desprotegida é a variável preditora, e a probabilidade de uso de preservativo, a variável critério. A Figura 2 mostra dados hipotéticos do exemplo.
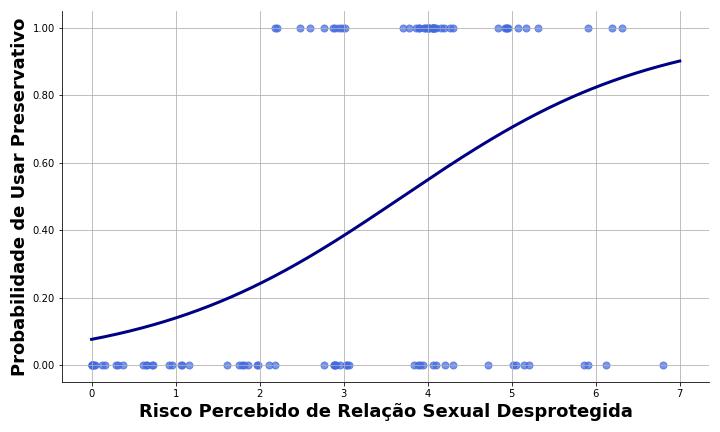
A Figura 2 sugere que quanto maior é o risco percebido de relação sexual desprotegida, maior é a probabilidade de uso de preservativo. Por meio desse modelo de regressão logística, poderíamos estimar os coeficientes que caracterizam a relação entre as variáveis de interesse.
Nesta seção, restringimo-nos ao caso da regressão logística binária simples, isto é, com variável critério com apenas dois níveis (usar preservativo vs. não usar preservativo) e com uma única variável preditora. No entanto, poderíamos testar modelos com uma variável critério com três ou mais níveis (i.e., regressão logística multinomial), assim como modelos com múltiplas variáveis preditoras (i.e., regressão logística múltipla).
Por exemplo, outras possíveis variáveis preditoras do uso de preservativo incluem o histórico prévio de infecções sexualmente transmissíveis, o grau de confiança no(a) parceiro(a) e a religião do(a) participante.
Quais são as diferenças entre a regressão linear e a regressão logística?
As três principais diferenças entre as regressões linear e logística (Figura 3) serão elaboradas a seguir.

Primeiramente, a variável critério é contínua ou aproximdamente contínua na regressão linear (e.g., nível de ansiedade, renda mensal e peso), mas categórica na regressão logística (e.g., aprovação em um teste, presença de uma doença e tipo de moradia).
Além disso, o tipo de relação entre as variáveis preditoras e a variável critério é linear na regressão linear (veja a Figura 1), mas não linear, na regressão logística (veja a Figura 2).
Por fim, a interpretação dos coeficientes difere entre os dois tipos de regressão. Na regressão linear, cada coeficiente representa a mudança na variável critério associada a uma unidade de mudança na variável preditora.
Por exemplo, nosso coeficiente na Figura 1 foi de b1 = –0,067, o que indica que, a cada aumento em uma unidade na qualidade de parentagem, esperamos uma diminuição de 0,067 no nível de agressividade.
Em contrapartida, na regressão logística, cada coeficiente representa o log-odds associado a uma unidade de mudança na variável preditora. No entanto, para facilitar a interpretação do coeficiente, convertemos seu valor para razão de chances (RC), aplicando a função exponencial, (e.g., RC = eb1).
Por exemplo, o coeficiente da Figura 2 foi b1 = 0,671. Sendo assim, esse valor equivale a RC = e0,671 = 1,96, com intervalo de confiança entre 1,43 e 2,69.
Em síntese, para cada unidade de aumento no risco percebido de relação sexual desprotegida, os participantes são 1,96 vezes mais prováveis de usar preservativos. Como o intervalo de confiança de 95% não inclui o valor nulo (RC = 1), concluímos que o risco percebido é um preditor significativo do uso de preservativo.
Conclusão
Neste post, apresentamos brevemente as regressões linear e logística, a fim de explicitarmos as diferenças entre elas. Esperamos que o post tenha sido útil. Aproveite e se inscreva em nosso canal do YouTube para ficar por dentro de nossas novidades!
Se você precisa aprender análise de dados, então faça parte da Psicometria Online Academy, a maior formação de pesquisadores quantitativos da América Latina. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).
Referência
Field, A. (2017). Discovering statistics using IBM SPSS Statistics (5th ed.). Sage.
Como citar este post
Lima, M. (2025, 28 de janeiro). Regressão linear e regressão logística: Quais são suas diferenças? Blog Psicometria Online. https://blog.psicometriaonline.com.br/diferenca-entre-regressao-linear-e-regressao-logistica/














Uma resposta
Boa tarde,
O que fazer quando os valores do OR são muito elevados na regressão logistica, por exemplo 18?
A variável é muito disporcional, tem grande percentagem no sim e pouca no não.
Obrigada.